


What kind of sparks can be generated from the collision of AI and Web3?
by Fred Li, research analyst at Ryze Labs

I. Introduction: The Development of AI+Web3
In recent years, the development of Artificial Intelligence (AI) and Web3 technologies has drawn global attention. AI, which simulates human intelligence, has achieved breakthroughs in facial recognition, natural language processing, and machine learning. These advancements have transformed various industries.
The AI industry's market size reached $200 billion in 2023, with key players like OpenAI, Character.AI, and Midjourney leading the way.
Simultaneously, Web3, an emerging network paradigm based on decentralized blockchain technology, is changing how we use the Internet. Web3 facilitates data sharing and control, user autonomy, and trust mechanisms through features like smart contracts, distributed storage, and decentralized identity verification. Its core concept is to free data from centralized authorities, giving users control over their data and the ability to share its value.
Currently, the Web3 industry's market value stands at $25 trillion, with significant contributions from Bitcoin, Ethereum, Solana, and applications like Uniswap and Stepn. These developments are drawing more people to the Web3 sector.
The combination of AI and Web3 is of great interest to builders and venture capitalists worldwide. Exploring how to integrate these technologies effectively is a valuable endeavor.
This article examines the current state of AI+Web3 development, exploring the potential value and impact of this fusion. We will introduce the basic concepts and characteristics of AI and Web3, examine their interrelationships, analyze the current status of AI+Web3 projects, and delve into their limitations and challenges. Through this research, we aim to provide insights and references for investors and professionals in related industries.
II. Interactions between AI and Web3
AI and Web3 development are like two sides of a balance scale. AI enhances productivity, while Web3 transforms production relationships. What kind of sparks can AI and Web3 create together? We will analyze the challenges and improvement opportunities in the AI and Web3 industries, and explore how they can help each other solve these challenges.
2.1 Challenges in the AI industry
To understand the challenges faced by the AI industry, we need to examine its core elements: computing power, algorithms, and data.

Computing Power:
Computing power refers to the ability to perform large-scale computations and processing. AI tasks often involve handling large amounts of data and conducting complex calculations, such as training deep neural network models. High-intensity computing power can accelerate model training and inference processes, improving AI system performance and efficiency. The development of hardware technologies like Graphics Processing Units (GPUs) and specialized AI chips like TPUs has played a crucial role. Nvidia, whose stock has surged in recent years, has gained a significant market share as a GPU provider, earning substantial profits.
Algorithms:
Algorithms are the core components of AI systems, using mathematical and statistical methods to solve problems and accomplish tasks. AI algorithms can be categorized into traditional machine learning and deep learning algorithms, with significant breakthroughs in deep learning in recent years. The selection and design of algorithms are crucial for AI system performance and effectiveness. Continuous improvement and innovation in algorithms enhance accuracy, robustness, and generalization capabilities. Different algorithms yield different results, so ongoing improvements are crucial for achieving desired outcomes.
Data:
The core task of AI systems is to extract patterns and regularities from data through learning and training. Data serves as the foundation for training and optimizing models. Large-scale data samples allow AI systems to learn more accurate and intelligent models. Rich datasets provide comprehensive and diverse information, enabling models to better generalize to unseen data and assist in solving real-world problems.
Having understood the core elements of AI, let's examine the challenges and issues AI faces in these areas:
Computing Power:
AI tasks often require substantial computational resources for model training and inference, especially for deep learning models. However, acquiring and managing large-scale computing power is expensive and complex. The cost, energy consumption, and maintenance of high-performance computing devices are significant issues. Startups and individual developers may find it difficult to obtain sufficient computing power.
Algorithms:
Despite significant successes in deep learning algorithms, there are still challenges and limitations. Training deep neural networks requires vast amounts of data and computational resources. For certain tasks, the interpretability and explainability of models may be insufficient. Additionally, robustness and generalization capabilities are important issues, as model performance on unseen data can be unstable. Finding the best algorithm to provide optimal services is an ongoing process.
Data:
Acquiring high-quality and diverse data remains a challenge. Some domains, such as healthcare, may have difficulty obtaining data. The quality, accuracy, and labeling of data pose challenges. Incomplete or biased data can lead to erroneous behavior or biases in models. Protecting data privacy and security is also a significant consideration.
There are also issues of interpretability and transparency. The black-box nature of AI models is a concern for the public. For applications such as finance, healthcare, and judiciary, the decision-making process of models requires interpretability and traceability, which current deep learning models often lack. Explaining the decision-making process of models and providing trustworthy explanations remains a challenge.
Additionally, many AI projects lack a clear business model, leaving many AI entrepreneurs puzzled.
2.2 Challenges faced by the Web3 industry
The Web3 industry faces several challenges that need to be addressed, such as data analysis, poor user experiences, and vulnerabilities in smart contract code. AI, as a productivity-enhancing tool, has significant potential to contribute in these areas.
Data Analysis and Predictive Capabilities:
There is room for improvement in data analysis and predictive capabilities within Web3. AI technology can profoundly impact the Web3 industry through intelligent analysis and mining using AI algorithms. Web3 platforms can extract valuable information from vast amounts of data, making more accurate predictions and decisions. This is crucial for risk assessment, market forecasting, and asset management in the decentralized finance (DeFi) space.
User Experience (UX):
User experience is another area where the Web3 industry can benefit from AI. Many decentralized applications (dApps) and blockchain platforms currently suffer from poor user experiences, hindering mainstream adoption. AI can improve UX by providing personalized recommendations, intelligent interfaces, and streamlined processes. Natural language processing (NLP) and computer vision techniques can enhance user interactions and simplify complex operations.
Security and Vulnerability of Smart Contracts:
The security and vulnerability of smart contracts are significant challenges in the Web3 industry. Smart contracts are self-executing contracts with terms written directly into code. However, vulnerabilities in the code can lead to financial losses or exploitation. AI can analyze and audit smart contracts, identifying potential vulnerabilities and suggesting improvements to enhance security. AI-powered security systems can also detect and respond to suspicious activities and attacks in real-time, protecting Web3 platforms and users from cyber threats.
Decentralized Governance:
Decentralized governance in Web3 platforms often involves complex decision-making processes. AI can assist in governance mechanisms by providing data-driven insights, sentiment analysis, and predictive analytics. AI algorithms can identify patterns and trends in community discussions and propose informed decisions based on data analysis. This can enhance the efficiency and effectiveness of decentralized governance systems.
III. Analysis of AI+Web3 Projects
The integration of AI and Web3 projects primarily focuses on two major aspects: leveraging blockchain technology to enhance AI performance and utilizing AI technology to improve Web3 projects.
Numerous projects have emerged around these aspects, including Io.net, Gensyn, Ritual, and others. In the following sections, we will analyze the current status and development of different sub-tracks related to AI empowering Web3 and Web3 empowering AI.
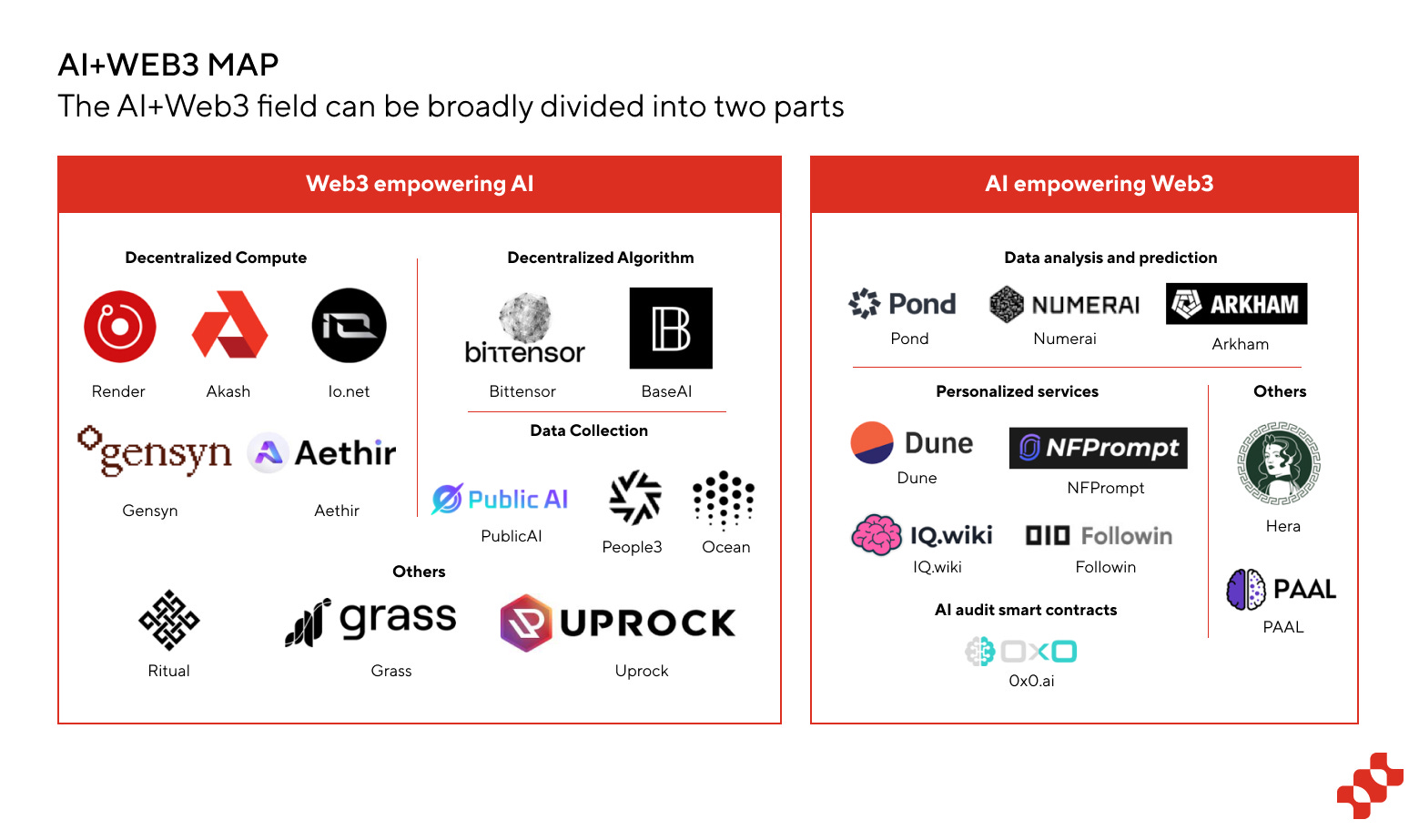
3.1 Web3 Empowering AI
3.1.1 Decentralized Computing Power
Since the launch of ChatGPT by OpenAI at the end of 2022, the AI field has experienced rapid growth. Within five days, ChatGPT reached 1 million users, a milestone that took Instagram over two months. By November 2023, it had 100 million weekly active users, solidifying AI as a major industry.
According to a Trendforce report, ChatGPT requires 30,000 NVIDIA A100 GPUs, and future models like GPT-5 will need even more. This has led to a competitive scramble among AI companies to secure sufficient computing power, resulting in a GPU shortage.
Before AI's rise, NVIDIA primarily served cloud services like AWS, Azure, and GCP. However, the AI boom has attracted new buyers, including major tech firms like Meta and Oracle, data platforms, and AI startups. Companies such as Meta and Tesla have ramped up purchases of custom AI models and internal research. Basic model companies like Anthropic and platforms like Snowflake and Databricks have also increased GPU acquisitions to support AI services.
According to Semi Analysis's "GPU Haves and Have-Nots" report, a few companies have over 20,000 A100/H100 GPUs, allowing extensive project utilization. These include cloud providers or firms with large-scale machine learning infrastructure, such as OpenAI, Google, Meta, Anthropic, Inflection, Tesla, Oracle, and Mistral.
Most companies, however, are GPU "have-nots," struggling with fewer GPUs and significant operational constraints. This includes prominent AI companies like Hugging Face, Databricks (MosaicML), Together, and even Snowflake, which are limited by GPU supply, hindering their competitiveness.
The GPU shortage has affected even leading AI companies. By the end of 2023, OpenAI had to temporarily close paid registrations due to insufficient GPU availability while seeking more supplies.
The imbalance between GPU demand and supply is critical. To address this, some Web3 projects are exploring the use of decentralized computing power services, such as Akash, Render, and Gensyn. These projects aim to incentivize users to provide idle GPU computing power through tokens, supporting AI clients.
The supply side can be divided into three main categories: cloud service providers, cryptocurrency miners, and enterprises. Cloud providers include major names like AWS, Azure, and GCP, as well as GPU cloud service providers like Coreweave, Lambda, and Crusoe. Users can resell idle computing power from these providers to generate income. With Ethereum's transition from Proof of Work (PoW) to Proof of Stake (PoS), idle GPU power from cryptocurrency miners is also a significant potential supply. Additionally, large enterprises like Tesla and Meta, which have purchased substantial GPUs for strategic purposes, can contribute their idle computing power.
Currently, players in this field can be broadly divided into two categories: those focusing on decentralized computing power for AI inference and those for AI training. The former includes projects like Render (primarily for rendering but also usable for AI computing), Akash, and Aethir. The latter includes projects like io.net (supporting both inference and training) and Gensyn, differing mainly in their specific computing power requirements.
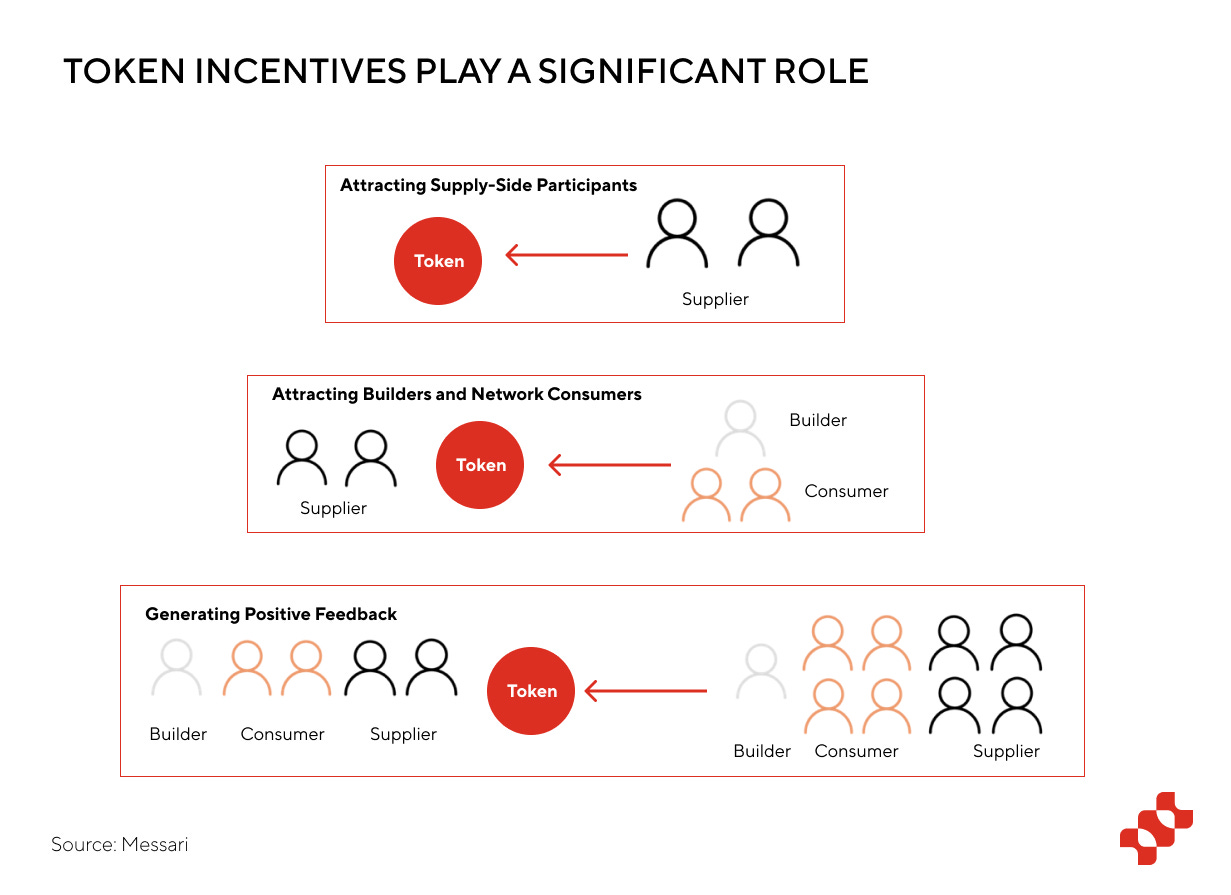
Let's first discuss projects focusing on AI inference. These projects incentivize users to contribute computing power through tokens and provide network services to meet demand, thus matching idle computing power supply with demand. Detailed information and analysis about these projects can be found in the research report published by Ryze Labs on DePIN.
The key aspect is the token incentive mechanism, which first attracts suppliers and then users, allowing the project to bootstrap and operate effectively. In this cycle, the supply side receives valuable token rewards, while the demand side benefits from more affordable and higher-quality services. As the token price rises, more participants and speculators are attracted, creating value capture.
The second category focuses on decentralized computing power for AI training, such as Gensyn and io.net (supporting both training and inference). These projects operate on a similar logic to those focusing on AI inference, attracting the supply side to contribute computing power through token incentives and providing it to the demand side.
io.net, a decentralized computing power network, currently has over 500,000 GPUs and has shown strong performance in the field of decentralized computing power projects. It has integrated the computing power of Render and Filecoin and continues to develop its ecosystem.

Additionally, Gensyn facilitates machine learning task allocation and rewards through smart contracts to drive AI training. The hourly cost of machine learning training on Gensyn is approximately $0.4, significantly lower than the cost of over $2 on AWS and GCP.
The Gensyn ecosystem involves four key participants: submitters, executors, validators, and reporters.
Submitters: Consumers who provide tasks to be computed and pay for AI training.
Executors: Perform the model training tasks and generate proofs of completion for validation.
Validators: Compare the executor's proofs with expected thresholds, linking the non-deterministic training process with deterministic linear computation.
Reporters: Verify the work of validators and raise objections to earn rewards when issues are discovered.
Gensyn aims to become a large-scale, cost-effective computing protocol for global deep learning models. However, why do most projects choose decentralized computing power for AI inference rather than training?
For those unfamiliar with AI training and inference, here are the differences:
AI Training: If we compare AI to a student, training is like providing the student with a large amount of knowledge and examples, understood as data. The AI learns from these examples. Since learning requires understanding and memorizing a vast amount of information, this process needs significant computational power and time.
AI Inference: Inference can be understood as using acquired knowledge to solve problems or take exams. During the inference stage, AI uses the acquired knowledge to provide answers rather than actively learning new information. Therefore, the computational requirements for inference are relatively lower.
It is evident that the computing power requirements for training and inference are significantly different. The availability of decentralized computing power for AI inference and training will be further analyzed in the subsequent challenge section.
In addition to decentralized computing power networks, other approaches are being explored to address the GPU supply shortage. One such approach is the development of more efficient and specialized hardware for AI workloads.
Companies like NVIDIA, AMD, and Intel are continuously working on developing GPUs and specialized accelerators optimized for AI tasks. These hardware solutions aim to provide higher performance and better energy efficiency for AI training and inference. By improving hardware capabilities, the demand for GPUs can be met more effectively, reducing the supply shortage.
Another approach is advancing AI algorithms and models to make them more efficient and require fewer computational resources. Researchers are developing algorithms and techniques that can achieve comparable or better performance with reduced computational requirements. This helps alleviate the strain on GPU resources and allows for more efficient use of the available supply.
Efforts are also being made to optimize the utilization of existing GPU resources. Techniques like virtualization and containerization enable the sharing and efficient allocation of GPUs among multiple users or applications. This can help maximize GPU utilization and mitigate the impact of supply shortages.
Lastly, governments and industry associations are taking steps to address the GPU supply shortage. They are working on initiatives to increase GPU production capacity and improve the supply chain. These efforts aim to stabilize the GPU supply and ensure a more balanced market.
Overall, addressing the GPU supply shortage requires a multi-faceted approach that includes developing specialized hardware, optimizing AI algorithms, efficient resource utilization, and collaborative efforts between industry stakeholders. These measures aim to alleviate the supply-demand imbalance and ensure a more sustainable availability of GPUs for AI workloads.
3.1.2 Decentralized Algorithmic Models
As mentioned in Chapter 2, the three core elements of AI are computational power, algorithms, and data. Since computational power can form a supply network through decentralization, can algorithms also follow a similar approach and form a supply network for algorithmic models?
Before analyzing projects in this field, let's first understand the significance of decentralized algorithmic models. Many might wonder why we need decentralized algorithm networks when we already have OpenAI.
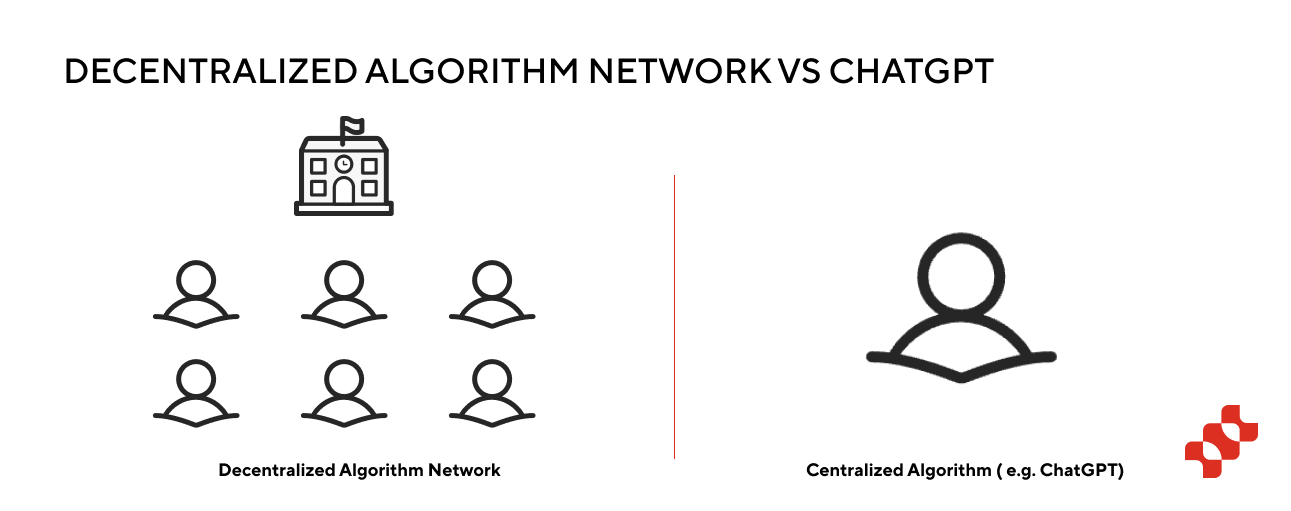
Essentially, a decentralized algorithm network is a marketplace for AI algorithm services that connects various AI models, each with its own expertise and skills. When users pose questions, the marketplace selects the most suitable AI model to provide answers. ChatGPT, developed by OpenAI, is an AI model that can understand and generate human-like text.
In simple terms, ChatGPT is like a highly capable student solving different types of problems, while the decentralized algorithm network is like a school with many students solving problems together. Although the current student (ChatGPT) is highly capable, there is significant potential for recruiting students globally in the long run.
Currently, some projects are exploring and experimenting in the field of decentralized algorithmic models. We will use the representative project Bittensor as a case study to understand development in this subfield.
In Bittensor, the supply side of algorithmic models (or miners) contribute their machine learning models to the network. These models analyze data and provide insights. Model suppliers are rewarded with the cryptocurrency token TAO for their contributions.
To ensure the quality of answers, Bittensor uses a unique consensus mechanism to determine the best answer within the network. When a question is posed, multiple model miners provide answers. Validators in the network then determine the best answer, which is sent back to the user.

The token TAO in Bittensor plays two main roles throughout the process. On one hand, it incentivizes miners to contribute algorithmic models to the network. On the other hand, users spend tokens to ask questions or have tasks completed by the network.
Since Bittensor is decentralized, anyone with internet access can join the network, either as a user posing questions or as a miner providing answers. This enables more people to leverage powerful artificial intelligence.
In summary, taking networks like Bittensor as an example, the field of decentralized algorithmic models has the potential to create a more open and transparent landscape. In this ecosystem, AI models can be trained, shared, and utilized in a secure and decentralized manner. Additionally, decentralized algorithmic model networks like BasedAI are also exploring similar concepts, using zero-knowledge proofs (ZK) to protect user and model interactive data privacy. This will be further discussed in the fourth section.
With the development of decentralized algorithmic model platforms, small companies can compete with large organizations in using cutting-edge AI tools, potentially having a significant impact on various industries.
3.1.3 Decentralized Data Collection
Training AI models requires a large supply of data. However, most Web2 companies currently retain user data for themselves. Platforms like X, Reddit, TikTok, Snapchat, Instagram, and YouTube prohibit data collection for AI training, creating a major obstacle for the AI industry.
On the other hand, some Web2 platforms sell user data to AI companies without sharing profits with the users. For example, Reddit reached a $60 million agreement with Google to allow AI model training on its posts. This situation, where collection rights are dominated by big capital and big data, has led to an overly capital-intensive industry direction.
In response, some projects are combining Web3 with token incentives to achieve decentralized data collection. For example, PublicAI allows users to participate in two roles on the platform:
AI Data Providers: Users find valuable content on platforms like X, tag it with #AI or #Web3, and send it to the PublicAI data center for collection.
Data Validators: Users log into the PublicAI data center and vote for the most valuable data for AI training.
In return, users receive token incentives, fostering a mutually beneficial relationship between data contributors and the AI industry.
In addition to PublicAI, many other projects are utilizing token incentives for decentralized data collection. For example:
Ocean Protocol: Tokenizes user data to serve AI.
Hivemapper: Collects map data through users' vehicle cameras.
Dimo: Collects users' car data.
WiHi: Collects weather data.
These projects, which collect data in a decentralized manner, are potential suppliers for AI training and exemplify Web3 empowering AI.
3.1.4 Utilize ZK to Protect Privacy in AI
Beyond the decentralization benefits brought by blockchain technology, zero-knowledge proofs (ZK) offer another crucial advantage. ZK technology protects privacy while enabling information verification.
In traditional machine learning, data is typically stored and processed centrally, posing risks of privacy breaches. Meanwhile, methods like data encryption or de-identification can limit the accuracy and performance of machine learning models.
ZK technology helps address this dilemma by balancing privacy protection and data sharing. Zero-Knowledge Machine Learning (ZKML) enables training and inference of machine learning models without revealing the original data, using zero-knowledge proofs. With ZKML, the data features and model results can be proven correct without disclosing the actual data content.
The primary goal of ZKML is to balance privacy protection and data sharing. It can be applied in scenarios such as medical health data analysis, financial data analysis, and cross-organizational collaboration. By using ZKML, individuals can protect their sensitive data while sharing it with others, gaining broader insights and collaboration opportunities without risking data privacy breaches.
Currently, this field is in its early stages, with most projects still exploring possibilities. For example, BasedAI proposes a decentralized approach that integrates Fully Homomorphic Encryption (FHE) with Large Language Models (LLM) to maintain data confidentiality. By embedding privacy into their distributed network infrastructure and utilizing Zero-Knowledge Large Language Models (ZK-LLM), user data is kept private throughout network operations.
Fully Homomorphic Encryption (FHE) is an encryption technique that allows computations on encrypted data without decryption. This means various mathematical operations performed on data encrypted with FHE produce the same results as if performed on unencrypted data, thus preserving user data privacy.
In addition to these categories, blockchain projects like Cortex support executing AI programs on-chain. Running machine learning programs on traditional blockchains is challenging due to inefficiencies in virtual machines when handling complex models. However, the Cortex Virtual Machine (CVM) uses GPUs to execute AI programs on-chain and is compatible with the Ethereum Virtual Machine (EVM). This means the Cortex chain can execute all Ethereum DApps and incorporate AI machine learning into these DApps, enabling decentralized, immutable, and transparent execution of machine learning models, with network consensus verifying every step of AI inference.
3.2 AI Empowering Web3
In the collision between AI and Web3, the assistance of AI to the Web3 industry is noteworthy. The core contribution of artificial intelligence lies in enhancing productivity. Consequently, there have been many attempts in areas such as AI auditing of smart contracts, data analysis and prediction, personalized services, and security and privacy protection.
3.2.1 Data Analysis and Prediction
Many Web3 projects are integrating existing AI services (such as ChatGPT) or developing their own to provide data analysis and prediction services for Web3 users. This includes providing investment strategies, on-chain analysis tools, and price and market forecasting through AI algorithms.
For example, Pond uses AI graph algorithms to predict valuable alpha tokens, offering investment advice for users and institutions. BullBear AI trains on users' historical data, price history, and market trends to provide accurate price trend predictions, helping users gain profits.
Investment competition platforms like Numerai use AI and large language models to predict the stock market. The platform provides high-quality data for training models, and participants submit daily predictions. Numerai calculates the performance of these predictions over the next month, and participants can stake NMR on their models to earn profits based on their performance.
Blockchain data analysis platforms like Arkham combine AI services. Arkham connects blockchain addresses with entities such as exchanges, funds, and whales, and displays key data and analysis to provide decision-making advantages for users. Arkham Ultra integrates AI to match addresses with real-world entities using algorithms, developed over three years with support from core contributors from Palantir and the founder of OpenAI.
3.2.2 Personalized Services
In Web2 projects, AI has been widely applied in search and recommendation to meet users' personalized needs. This trend is also seen in Web3 projects, where many teams optimize user experience by integrating AI.
For example, Dune, a well-known data analysis platform, recently introduced the Wand tool, which uses large language models to write SQL queries. With the Wand Create feature, users can generate SQL queries based on natural language questions, making it convenient for those unfamiliar with SQL to perform searches.
Additionally, some Web3 content platforms have begun integrating ChatGPT for content summarization. For instance, the Web3 media platform Followin uses ChatGPT to summarize viewpoints and provide the latest updates in specific fields. IQ.wiki, a Web3 encyclopedia platform, aims to be a primary source of objective and high-quality knowledge related to blockchain technology and cryptocurrencies. It makes blockchain more accessible and provides users with trustworthy information by integrating GPT-4 to summarize wiki articles. Kaito, a search engine based on large language models (LLM), is dedicated to becoming a Web3 search platform, transforming how Web3 information is accessed.
In content creation, projects like NFPrompt reduce user creation costs. NFPrompt allows users to generate NFTs more easily with AI, thereby lowering creative costs and providing various personalized services during the creative process.
3.2.3 AI Auditing of Smart Contracts
In the Web3 space, auditing smart contracts is a crucial task. Using AI to audit smart contract code can efficiently and accurately identify vulnerabilities.
As Vitalik Buterin mentioned, one of the biggest challenges in the cryptocurrency space is code errors. AI offers the exciting possibility of significantly simplifying the use of formal verification tools to prove code properties. Achieving this could lead to an error-free Ethereum Virtual Machine (EVM), enhancing security across the space.
For example, the 0x0.ai project provides an AI-powered smart contract auditor. This tool uses advanced algorithms to analyze smart contracts, identifying potential vulnerabilities or issues that could lead to fraud or security risks. Machine learning techniques are used to identify patterns and anomalies in the code, flagging potential issues for further review.
Beyond auditing, there are other native AI use cases in the Web3 space. For instance, PAAL helps users create personalized AI bots that can be deployed on Telegram and Discord to serve Web3 users. Hera, an AI-driven multi-chain DEX aggregator, uses AI to find the best trading paths for the widest range of tokens and token pairs. Overall, AI empowers Web3 primarily as a tool-level assistance.
IV. Limitations and Challenges of AI+Web3 Projects
4.1 Real-world barriers to decentralized computing power
Many current AI+Web3 projects focus on decentralized computing power, using token incentives to encourage global users to supply computational resources. While this is an innovative approach, it faces several practical challenges:
Compared to centralized computing power service providers, decentralized computing power products typically rely on nodes and participants distributed globally. This distribution can lead to potential network latency and instability between nodes, causing performance and stability issues that may be inferior to centralized alternatives.
Additionally, the availability of decentralized computing power products is influenced by the balance of supply and demand. Insufficient suppliers or excessive demand can lead to resource shortages or an inability to meet user needs.
Furthermore, decentralized computing power products generally involve more technical complexity compared to centralized alternatives. Users may need to understand and manage aspects such as distributed networks, smart contracts, and cryptocurrency payments, increasing the complexity and cost of usage.
After in-depth discussions with numerous decentralized computing power projects, it has been found that current decentralized computing power is primarily limited to AI inference rather than AI training.
Next, I will address four specific questions to help understand the underlying reasons:
Why do most decentralized computing power projects focus on AI inference rather than AI training?
What makes NVIDIA stand out? What are the challenges in achieving decentralized computing power training?
What will be the endgame for decentralized computing power projects like Render, Akash, and io.net?
What will be the endgame for decentralized algorithm projects like Bittensor?
Let's explore these questions step by step:
1)Focus on AI Inference Over Training:
Most decentralized computing power projects focus on AI inference rather than training due to the different requirements for computing power and bandwidth. To understand this better, consider AI as a student:
AI Training: Training is like providing the AI with a large amount of knowledge and examples (data). The AI learns from these examples, requiring significant computational power and time to understand and memorize vast amounts of information.
AI Inference: Inference is like using the acquired knowledge to solve problems or take exams. During the inference phase, the AI uses learned knowledge to provide answers without acquiring new knowledge. Therefore, the computational requirements for inference are relatively low.
The fundamental difference between the two lies in the large-scale data and high bandwidth needed for AI training, making decentralized training challenging. Inference, on the other hand, requires much less data and bandwidth, making it more feasible for decentralized computing power.
For large-scale models, stability is crucial. Interruptions in training require restarting the process, incurring substantial costs. However, tasks with lower computational requirements, such as AI inference or training medium-sized models in niche scenarios, can be achieved within the decentralized computing power network. Relatively large node service providers can cater to these higher computational demands.
2)So, where are the bottlenecks related to data and bandwidth? Why is decentralized training challenging to achieve?
Decentralized training of large-scale models involves two key elements: single-card computing power and multi-card parallelization.
Single-Card Computing Power:
All centers requiring large-scale model training can be compared to supercomputing centers, akin to organs in a human body, with GPU units as cells. If the computing power of an individual cell (GPU) is high, the overall computing power (number of cells × individual cell power) is also significant.
Multi-Card Parallelization:
Training a large-scale model often involves processing hundreds of billions of gigabytes of data. Supercomputing centers dedicated to large-scale model training require at least tens of thousands of A100 GPUs as a foundation. Training a large-scale model is not a simple sequential process done on one GPU after another. Different parts of the model are trained on different GPUs, and the training of one part may require results from another, introducing the need for multi-card parallelization.
Why is NVIDIA So Dominant?
NVIDIA's dominance and skyrocketing market value are due to two main aspects: the CUDA software ecosystem and NVLink for multi-card communication.
CUDA Software Ecosystem: Having a compatible software ecosystem is crucial. NVIDIA's CUDA system is a prime example, and building a new system is challenging, similar to creating a new language with high replacement costs.
NVLink for Multi-Card Communication: Training large models requires high-speed communication and synchronization between GPUs. NVIDIA's NVLink technology provides efficient communication between GPUs, enabling effective parallelization and scaling of training processes, giving NVIDIA an edge over competitors like AMD, Huawei, and Horizon Robotics.
Challenges in Decentralized Training:
Achieving decentralized training in the computing power space faces significant challenges in replicating the capabilities of supercomputing centers, such as high-performance single-card computing power and efficient multi-card parallelization. Overcoming these challenges requires significant advancements in hardware, software, and communication technologies.
The first point explains why it is difficult for AMD, Huawei, and Horizon Robotics to catch up, and the second point explains why decentralized training is challenging to achieve.
3)What will be the ultimate form of decentralized computing power?
Decentralized computing power currently faces challenges in training large-scale models, mainly due to the need for stability in such training. If the training process is interrupted, it must be restarted, incurring high sunk costs. The requirements for multi-card parallelization are demanding, and bandwidth is limited by physical distance. NVIDIA's NVLink facilitates multi-card communication, but within a supercomputing center, NVLink restricts the physical distance between GPUs. As a result, decentralized computing power cannot form a unified cluster for large-scale model training.
However, it is feasible to achieve lower-demand computing requirements, such as AI inference or training smaller models for specific niche scenarios. When there are relatively large node service providers in a decentralized computing power network, there is potential to meet these significant computing demands. Additionally, scenarios like edge computing for rendering are easier to implement.
4)What will be the ultimate form of decentralized algorithm models?
The ultimate form of decentralized algorithm models depends on the future of AI. The AI landscape may consist of 1-2 closed-source model giants (such as ChatGPT) alongside a diverse range of models. In this context, application-layer products need not be tied to a single large-scale model but can collaborate with multiple large-scale models. From this perspective, the approach taken by Bittensor holds significant potential.
4.2 The combination of AI and Web3 is still rudimentary
Currently, in projects combining Web3 and AI, especially those involving AI in Web3 applications, most only superficially use AI without demonstrating deep integration between AI and cryptocurrencies. This superficial application can be seen in two aspects:
Firstly, whether using AI for data analysis and prediction, AI-powered recommendations and search, or code auditing, the integration is not significantly different from Web2 projects. These projects simply use AI to enhance efficiency and perform analysis without showcasing native integration and innovative solutions between AI and cryptocurrencies.
Secondly, many Web3 teams integrate AI primarily at the marketing level, using the concept of AI purely for promotion. They apply AI technology in very limited areas, creating an illusion of a close connection between the project and AI. However, in terms of true innovation, these projects still have a long way to go.
Although current Web3 and AI projects have these limitations, it’s important to recognize that we are in the early stages of development. In the future, we can expect more in-depth research and innovation to achieve closer integration between AI and cryptocurrencies and create more native and meaningful solutions in finance, decentralized autonomous organizations (DAOs), prediction markets, NFTs, and more.
4.3 Tokenomics serves as a buffer for the narrative of AI projects.
As mentioned earlier, regarding the business model challenge for AI projects, with more large models gradually becoming open source, many AI+Web3 projects struggle to find development and financing opportunities in the Web2 space. As a result, they overlay the narrative of Web3 and tokenomics to encourage user participation.
However, the crucial question is whether the integration of tokenomics truly addresses the practical needs of AI projects or if it is purely a narrative or short-term value pursuit.
Currently, most AI+Web3 projects are still far from practical stages. It is hoped that more diligent and thoughtful teams can go beyond tokenization as a mere spectacle for AI projects and instead genuinely fulfill practical use cases.
V. Conclusion
Numerous cases and applications are emerging in AI+Web3 projects. Firstly, AI technology can provide more efficient and intelligent application scenarios for Web3. Through AI's data analysis and prediction capabilities, users in Web3 can access better tools for investment decision-making and other scenarios. Additionally, AI can audit smart contract code, optimize the execution process of smart contracts, and improve blockchain performance and efficiency. Furthermore, AI technology can offer more accurate and intelligent recommendations and personalized services for decentralized applications, enhancing user experience.
At the same time, the decentralized and programmable nature of Web3 offers new opportunities for AI development. Projects that leverage decentralized computing power provide new solutions to the scarcity of AI computing power through token incentives. Web3's smart contracts and distributed storage mechanisms also offer broader space and resources for sharing and training AI algorithms. The user autonomy and trust mechanisms in Web3 bring new possibilities for AI development. Users can choose to participate in data sharing and training, thereby improving data diversity and quality, further enhancing AI model performance and accuracy.
Although current cross-over projects between AI and Web3 are still in the early stages and face many challenges, they also bring many advantages. For example, while decentralized computing power products have their drawbacks, they reduce reliance on centralized institutions, provide greater transparency and auditability, and enable wider participation and innovation. For specific use cases and user needs, decentralized computing power products may be a valuable choice. Similarly, decentralized data collection projects offer benefits such as reducing reliance on a single data source, providing wider data coverage, and promoting data diversity and inclusivity. It is necessary to weigh these pros and cons and implement appropriate management and technical measures to overcome challenges and ensure that decentralized data collection projects positively impact AI development.
Overall, the integration of AI and Web3 provides endless possibilities for future technological innovation and economic development. By combining AI's intelligent analysis and decision-making capabilities with the decentralization and user autonomy of Web3, a more intelligent, open, and fair economic and social system can be built in the future.