


A Thorough Review of OpenAI’s Newest Paper: GPTs are GPTs
An Early Look at the Labor Market Impact Potential of Large Language Models
By Shira Eisenberg, intern and Mona Hamdy, CSO
OpenAI, OpenResearch, and University of Pennsylvania released a paper titled GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models. The following is a thorough review and dissection of the paper, made as brief as yet detailed as possible.
Overview
The paper investigates the impact of Generative Pre-trained Transformer (GPT) models on the U.S. labor market, using a new rubric and metric of exposure. The findings suggest that around 80% of the workforce could have at least 10% of their tasks affected by GPTs, and 19% of workers may experience an impact on at least 50% of their tasks. Occupations with higher wages are more exposed to GPTs, and this exposure spans across industries, regardless of their recent productivity growth. The study concludes that GPTs have the characteristics of general-purpose technologies, with potential economic, social, and policy implications.
Although the work remains highly theoretical, using human annotators and GPT-4 as classifiers to apply the new framework to occupational data from the U.S. economy, the conclusion emphasizes the need for further research to explore the broader implications of GPT advancements, such as their potential to augment or displace human labor, impact on job quality, inequality, skill development, and other outcomes.
Policymakers and stakeholders need to understand the capabilities and effects of GPTs on the workforce to make informed decisions and navigate the complex landscape of AI in shaping the future of work.

Capabilities
While the public’s attention has been focused on the rapid advancement of GPT capabilities, there are many other architectures beyond just the Generative Pre-trained Transformer (GPT) models that fall under the umbrella of large language models (LLMs).
LLMs have the ability to process and generate a diverse range of sequential data including assembly language, protein sequences, code and even chess games, demonstrating their versatility beyond just natural language applications. Still, their performance remains extremely prompt-dependent, with the quality of output depending both on the model and input rather than the model alone. This has led to the emergent need for a new profession, prompt engineering. Recent models released by OpenAI, Google, and NVIDIA have expanded their capabilities to include multimodal functionality, allowing for the processing of image and eventually video data.
The inspiration behind the study under review stems not only from the progression of the models themselves but also from the wide scope, scale, and potential of the supporting technologies developed around them. To fully harness the power of LLMs, it is essential to integrate them into larger systems, rather than just developing sheer wrappers around them. LLMs can enable new forms of software and machine communication, paving the way for custom neural search applications using embeddings, and tasks like summarization and classification. In such cases, it may be challenging to distinguish between generative AI and other classes of AI.
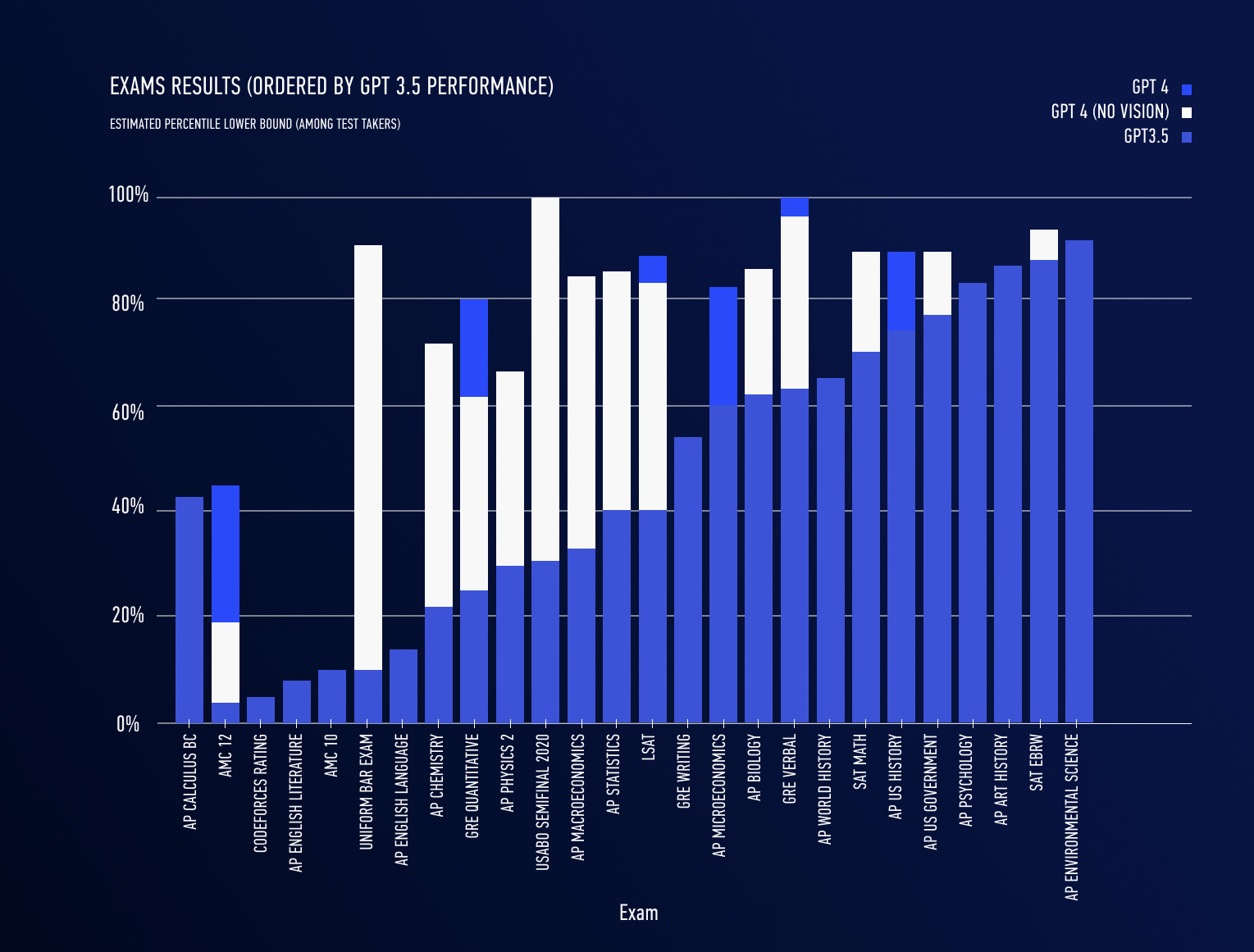
Figure: Exam performance improvements of GPT-4 over GPT-3.5, from OpenAI’s 2023 GPT-4 paper
In order to understand the development of LLM technologies and their potential impact on the labor market, the paper presents a novel framework that assesses LLM capabilities and their potential effects on various jobs. This rubric evaluates the overall susceptibility of tasks to GPTs, where exposure serves as an indicator for potential economic impact. It does not, however, differentiate between labor-enhancing or labor-displacing consequences. This is to say, it remains uncertain whether the study is truly examining GPTs’ potential to replace jobs or simply their ability to enhance existing work.
Both human annotators and GPT-4 were deployed as classifiers to apply this framework to occupational data from the U.S. economy primarily sourced from the O*NET database.
Preliminary Discussion of Findings (Detailed discussion further down)
The paper under review consistently reveals that most occupations display some level of vulnerability to LLMs, according to both human and GPT-4 annotations. Surprisingly, higher-wage occupations exhibit greater exposure, which contradicts previous research on overall machine learning exposure. The study reveals a negative correlation between exposure to LLMs and jobs that heavily rely on science and critical thinking skills, whereas jobs that require programming and writing skills show a positive association with LLM exposure. Furthermore, workers with higher barriers to entry in their professions experienced increased LLM exposure.
The research also examines industry-specific exposure, revealing that information processing and general information work have high exposure, while manual labor industries such as manufacturing, agriculture, and mining exhibit lower exposure. The study suggests that LLM impacts will likely be widespread and long-lasting, even if we halt the development of new LLM capabilities today, as some argue we should.
This potential impact is amplified when considering the development of complementary technologies. These characteristics collectively indicate that GPTs function as general-purpose technologies (also GPTs), hence the title “GPTs are GPTs.” The paper’s key contributions include providing measurements of LLM impact potential and demonstrating the efficient and scalable application of LLMs in developing such measurements. Moreover, the research highlights the general-purpose potential of LLMs.
However, the future trajectory of LLM development and application may prove difficult for policymakers to anticipate and regulate, as is the case with most general-purpose technologies. Much of the potential of these algorithms will manifest across a wide range of economically valuable use cases, giving rise to new types of work, as is already the case with the profession of prompt engineering. While the research in this paper measures current technical feasibility, it may not capture the evolving impact potential of LLMs over time.
Dissection of Methodology
Exposure Rubric
For the sake of brevity, we considered leaving the rubric (included in the appendix of the paper) out of this article or providing an abbreviated rubric; however, upon later thought, we found it critical to include the full rubric in order to truly demonstrate how theoretical the evaluation in this work was. This is not to detract from its validity, but simply to show it as highly reliant on hypothetical and qualitative reports from human workers.
Below is a full version of the rubric provided to workers and GPT-4 along with occupational data from the U.S. economy. Key definitions are highlighted.
Exposure Rubric:
Consider the most powerful OpenAI large language model (LLM). This model can complete many tasks that can be formulated as having text input and text output where the context for the input can be captured in 2000 words. The model also cannot draw up-to-date facts (those from <1 year ago) unless they are captured in the input.
Assume you are a worker with an average level of expertise in your role trying to complete the given task. You have access to the LLM as well as any other existing software or computer hardware tools mentioned in the task. You also have access to any commonly available technical tools accessible via a laptop (e.g. a microphone, speakers, etc.). You do not have access to any other physical tools or materials.
Please label the given task according to the rubric below.
Equivalent quality means someone reviewing the work would not be able to tell whether a human completed it on their own or with assistance from the LLM.
If you aren’t sure how to judge the amount of time a task takes, consider whether the tools described exposed the majority of subtasks associated with the task.
## E1 - Direct exposure
Label tasks E1 if direct access to the LLM through an interface like ChatGPT or the OpenAI playground alone can reduce the time it takes to complete the task with equivalent quality by at least half. This includes tasks that can be reduced to: - Writing and transforming text and code according to complex instructions, - Providing edits to existing text or code following specifications, - Writing code that can help perform a task that used to be done by hand, - Translating text between languages, - Summarizing medium-length documents, - Providing feedback on documents, - Answering questions about a document, - Generating questions a user might want to ask about a document, - Writing questions for an interview or assessment, - Writing and responding to emails, including ones that involve refuting information or engaging in a negotiation (but only if the negotiation is via written correspondence), - Maintain records of written data, - Prepare training materials based on general knowledge, or - Inform anyone of any information via any written or spoken medium
## E2 - Exposure by LLM-powered applications
Label tasks E2 if having access to the LLM alone may not reduce the time it takes to complete the task by at least half, but it is easy to imagine additional software that could be developed on top of the LLM that would reduce the time it takes to complete the task by half. This software may include capabilities such as: - Summarizing documents longer than 2000 words and answering questions about those documents, - Retrieving up-to-date facts from the Internet and using those facts in combination with the LLM capabilities, - Searching over an organization’s existing knowledge, data, or documents and retrieving information, - Retrieving highly specialized domain knowledge, - Make recommendations given data or written input, - Analyze written information to inform decisions, - Prepare training materials based on highly specialized knowledge, - Provide counsel on issues, and - Maintain complex databases.
## E3 - Exposure given image capabilities
Suppose you had access to both the LLM and a system that could view, caption, and create images as well as any systems powered by the LLM (those in E2 above). This system cannot take video as an input and it cannot produce video as an output. This system cannot accurately retrieve very detailed information from image inputs, such as measurements of dimensions within an image. Label tasks as E3 if there is a significant reduction in the time it takes to complete the task given access to a LLM and these image capabilities: - Reading text from PDFs, - Scanning images, or - Creating or editing digital images according to instructions.
The images can be realistic but they should not be detailed. The model can identify objects in the image but not relationships between those options
## E0 - No exposure
Label tasks E0 if none of the above clearly decrease the time it takes for an experienced
worker to complete the task with high quality by at least half. Some examples: - If a task requires a high degree of human interaction (for example, in-person demonstrations) then it should be classified as E0. - If a task requires precise measurements then it should be classified as E0. - If a task requires reviewing visuals in detail, it should be classified as E0. - If a task requires any use of a hand or walking then it should be classified as E0. - Tools built on top of the LLM cannot make any decisions that might impact human livelihood (e.g. hiring, grading, etc.). If any part of the task involves collecting inputs to make a final decision (as opposed to analyzing data to inform a decision or make a recommendation) then it should be classified as E0. The LLM can make recommendations. - Even if tools built on top of the LLM can do a task, if using those tools would not save an experienced worker significant time completing the task, then it should be classified as E0. - The LLM and systems built on top of it cannot do anything that legally requires a human to perform the task. - If there is existing technology not powered by an LLM that is commonly used and can complete the task then you should mark the task E0 if using an LLM or LLM-powered tool will not further reduce the time to complete the task.
When in doubt, you should default to E0.
## Annotation examples:
Occupation: Inspectors, Testers, Sorters, Samplers, and Weighers Task: Adjust, clean, or repair products or processing equipment to correct defects found during inspections. Label (E0/E1/E2/E3): E0 Explanation: The model does not have access to any kind of physicality, and more than half of the task (adjusting, cleaning and repairing equipment) described requires hands or other embodiment.
Occupation: Computer and Information Research Scientists Task: Apply theoretical expertise and innovation to create or apply new technology, such as adapting principles for applying computers to new uses. Label (E0/E1/E2/E3): E1 Explanation: The model can learn theoretical expertise during training as part of its general knowledge base, and the principles to adapt can be captured in the text input to the model.
Activity: Schedule dining reservations. Label (E0/E1/E2/E3): E2 Explanation: Automation technology already exists for this (e.g. Resy) and it’s unclear what an LLM offers on top of using that technology (no-diff). That said, you could build something that allows you to ask the LLM to make a reservation on Resy for you.
As demonstrated in the example annotations, while workers were asked to provide explanations for their rankings, these explanations can be a bit arbitrary and are somewhat disputable. Moreover, they do not lead directly to the conclusion of a job being automatable. They instead support a hypothesis of a job being augmentable or enhanceable.
For example, the task of “applying theoretical expertise and innovation to create or apply new technology, such as adapting principles for applying computers to new uses,” for the occupation of “Computer and Information Research Scientist,” was labeled E1, direct exposure, the highest level of exposure, with an explanation that “the model can learn theoretical expertise during training as part of its general knowledge base, and the principles to adapt can be captured in the text input to the model.” While this does satisfy the requirements for an E1 ranking, since “direct access to the LLM through an interface like ChatGPT or the OpenAI playground alone can reduce the time it takes to complete the task with equivalent quality by at least half,” a human-in-the-loop system would still be required for the task to be completed, with a qualified human worker doing the prompting. This provides more evidence of the task and profession being augmentable than automatable.
It is unclear how evaluations based on this rubric lead to conclusions of jobs being displaceable.
O*NET Data and Data on Wages, Employment, and Demographics
Please see section 3.1 of the paper for information on the O*NET dataset used. For the sake of brevity, we will only state that the dataset includes information on 1,016 occupations, including their respective Detailed Work Activities (DWAs) and tasks. The dataset came out to 19,265 tasks and 2,087 DWAs.
Employment and wage data was collected from the 2020 and 2021 Occupational Employment series provided by the Bureau of Labor Statistics and detailed occupational titles, the number of workers in each occupation, and occupation-level employment projections for 2031, typical education required for entry in an occupation and on-the-job training required to attain competency in an occupation.
Human Ratings and GPT-4 Ratings: Mechanics
Both human ratings and GPT-4 generated annotations were collected using the exposure rubric. These data collections underlie the bulk of the paper’s analyses.
To ensure the quality of human ratings, the authors personally labeled a large sample of tasks and DWAs. They also enlisted experienced human annotators who have extensively reviewed GPT outputs in OpenAI’s prior work.
The paper mentions slight modifications to the rubric, which was used as a prompt to GPT-4, to enhance agreement with a set of human labels. It is unclear what is meant by enhancing agreement.
Limitations of Paper Methodology
The paper acknowledges the limitations of its methodology, particularly in the subjectivity of human judgments and in measuring GPTs with GPT-4.
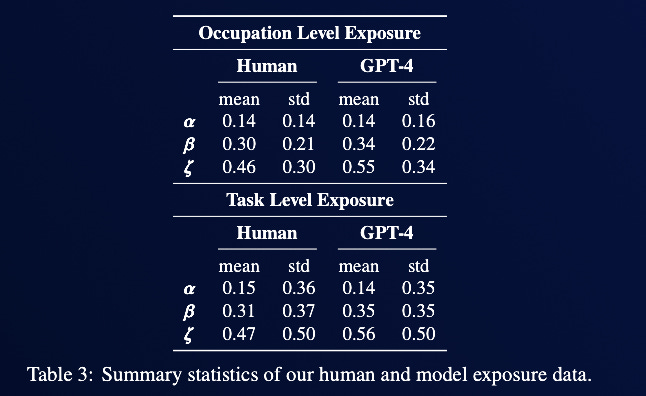
The limitations of human judgment are pervasive, as is usually the case in studies with human annotators. Although the study employs annotators who are familiar with the GPT models’ capabilities, the group was not occupational diverse, potentially leading to biased judgments regarding the models’ reliability and effectiveness in performing tasks within unfamiliar occupations. That said, human raters and GPT-4 ratings show a high degree of agreement about GPT exposure by occupation. GPT-4 ratings tend to be lower than human ratings. Near the top end of exposure ratings, humans are on average more likely to rate an occupation as exposed. The plots below show this.

As recent research indicates that GPT-4 serves as an effective discriminator and is capable of applying intricate taxonomies and responding to changes in wording and emphasis, the outcomes of the GPT-4 task classification are sensitive to alterations in the rubric’s wordings, the prompt’s order and composition, the presence or absence of specific examples in the rubric, the level of detailed provided, and key term definitions. In other words, outputs are extremely prompt-dependent, as are most outputs with GPTs. By refining the prompt using a small validation set, it is possible to improve the alignment between the model outputs and the intended rubric.
The authors made a conscious decision to use slightly different rubrics for human annotators and GPT-4, guiding the model towards reasonable labels without overly influencing the human annotators. Consequently, they employ multiple annotation sources, but none of these should be considered the definitive ground truth in comparison to the others. Due to the incredible sensitivity of GPT-4 ratings, the paper primarily presents results from human annotators, which, as aforementioned, are subject to the subjectivity of human judgment. That said, a notable level of agreement is observed between human and GPT-4 ratings at the occupation level.
Further limitations are presented relating to the validity of the task-based framework, relative vs absolute measures, lack of expertise and task interpretation of human annotators, forward-looking and the subjectivity of annotations to change with some early evidence, and sources of disagreement, including tasks or activities, where while an LLM could theoretically help or accomplish a task, adopting it to do so would require multiple people to change their habits or expectations, tasks or activities where there is currently some regulation that requires human oversight or empathy, and tasks or activities where there already exists a technology that can reasonably automate a task.
Discussion of Results and Summary Statistics
Whether the results indicate job displaceability or augmentability, it is still clear that GPTs are general-purpose technologies. Over time, we can assess this by observing the long-term impact of these models’ capabilities and the growth of complementary applications and systems. At this early stage, the paper’s primary focus was to test the hypothesis that GPT language models have a pervasive influence on the economy.
The findings suggest that GPTs have the potential to significantly affect a diverse range of occupations within the U.S. economy, demonstrating a key attribute of general-purpose technologies.
Summary statistics indicate that, for the median occupation, approximately 15% of tasks are directly exposed to GPTs. This figure increases to over 30% for 𝛽, defined as the sum of E1 and 0.5*E2, where the weight on E2 is intended to account for exposure when deploying the technology via complementary tools and applications necessitates additional investment, and surpasses 50% for ξ, defined as the sum of E1 and E2, an upper bound of exposure that provides an assessment of maximal exposure to GPT and GPT-powered software.
For more information on summary statistics and what they mean, see section 4.1 of the paper.
In summary, the potential for GPTs to either automate or enhance tasks is vast, but these models must first be integrated into larger systems to fully realize their potential. Anticipating the extent of human oversight needed is difficult, particularly for tasks where the model capabilities meet or exceed human performance levels. Although the need for human supervision may initially hinder the adoption and dissemination rate, users of GPTs and GPT-driven systems are expected to become more familiar with the technology over time. This familiarity will help users better understand when and how to trust the outputs generated by these models.
This analysis is sound.
As for wages and employment, the distribution of exposure is similar across occupations, which suggests worker concentration in occupations is not highly correlated with occupational exposure to GPTs or GPT-powered software. It may, however, be more highly correlated with investment in developing domain-specific GPT-powered software.
As for skill importance, the findings indicate the importance of science and critical thinking skills are strongly negatively associated with exposure, suggesting that occupations requiring these skills are less likely to be impacted by current language models, while programming and writing skills show a strong positive correlation with exposure, implying that occupations involving these skills are more vulnerable to influence by language models.
As for barriers to entry in occupations and typical education required for entry, the analysis suggests that individuals holding Bachelor’s, Master’s, and professional degrees are more exposed to GPTs and GPT-powered software than those without formal educational credentials. This is likely because jobs requiring more education have more text-based resources, which were likely included in the models’ training data.

The table above displays that occupations with the highest exposure are among those with the highest education requirements. Among those called out for high exposure are writers and authors and blockchain engineers. It is easy to dispute some of these ratings, as it is extremely unlikely a mathematician’s job would be highly automatable. This shows the high subjectivity of ratings to human judgment. That said, occupations listed in this table are those where it is estimated that GPTs and GPT-powered software are able to save workers a significant amount of time completing a large share of their tasks, but it does not necessarily suggest that their tasks can be fully automated by these technologies.
Discussion of GPTs as General Purpose Technologies, Implications for Public Policy, and Limitations
This paper explores the possibility of classifying GPTs as general-purpose technologies, which must meet three core criteria: improvement over time, pervasiveness throughout the economy, and the ability to spawn complementary innovations. The paper presents evidence supporting the latter two criteria, finding that GPTs have widespread impacts across the economy and that complementary innovations enabled by GPTs, particularly through software and digital tools, have broad applications in economic activity.
The findings suggest that GPT-powered software has more than twice the average impact on task exposure compared to LLMs alone. While these models are already relevant to a significant number of workers and tasks, the software innovations they spawn could have an even broader impact.
Widespread adoption of these models depends on identifying bottlenecks, with factors such as trust, cost, flexibility, preferences, and incentives playing a crucial role in adopting tools built on LLMs. Ethical and safety risks, such as bias and misalignment, also influence adoption. The adoption of LLMs will differ across economic sectors due to factors like data availability, regulatory quality, innovation culture, and power distribution. A comprehensive understanding of LLM adoption by workers and firms requires further exploration of these intricacies.
Two possible scenarios are that time savings and seamless application will be more important than quality improvement for most tasks or that the initial focus will be on augmentation, followed by automation. In the latter case, an augmentation phase, where jobs become more precarious, could precede full automation.
The introduction of automation technologies, including LLMs, has been associated with increased economic disparity and labor disruption, which can lead to negative downstream effects. This highlights the need for societal and policy preparedness for the potential economic disruption caused by LLMs and their complementary technologies. While this paper does not provide specific policy recommendations, previous research has suggested important directions for policy related to education, worker training, safety net program reforms, and more.
This study has various limitations, including its focus on the United States, which may limit the generalizability of its findings to other countries with different industrial organizations, technological infrastructures, regulatory frameworks, linguistic diversity, and cultural contexts. Future research should expand the study's scope and share methods to encourage further investigation.
Two additional areas of research should be considered: exploring GPT adoption patterns across sectors and occupations and examining the actual capabilities and limitations of state-of-the-art models in relation to work activities beyond exposure scores. Despite recent advances in multimodal capabilities, this study did not consider vision capabilities in the direct GPT-exposure ratings. Future work should assess the impact of such capability advances as they develop and recognize potential discrepancies between theoretical and practical performance, especially in complex, open-ended, and domain-specific tasks.
Concluding Remarks
In the coming years, creators, developers, and innovators will face a critical decision: either continue working for an organization that may actively seek to automate their roles or venture independently, leveraging AI to build applications and establish their own enterprises.
Specifically, in the realm of cryptocurrency, there lies an opportunity to harness AI to exponentially accelerate the development of decentralized finance, governance, identity, and data systems. This becomes increasingly essential as AI continues to proliferate, contributing to work that truly matters.
Jobs with no exposed tasks tend to be those that do not require a college education and often fail to provide a living wage, as shown in the table below.

It may be prudent for the U.S. to begin establishing safety nets for job displacement, even while the economy is still in an augmentation phase, rather than waiting for full automation to take hold.